Document Parser
To showcase how we can process basically any type of document that can be represented as an image (or directly as text), I've developed a small proof of work app using two different llms.
To get it working we first have to install https://huggingface.co/kirp/kosmos2_5 hugginface pull request which is currently not merged.
Setup Extractor LLM
To extract information from text I have used the googles gemma-2b-it model. Even a 2b model for an information extraction task is probably a bit overkill.
The first step is to load the gemma 2 model (You will need an access token for this)
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
import transformers
import torch
from huggingface_hub import login
import re
import torch
import requests
from PIL import Image, ImageDraw
from transformers import AutoProcessor, Kosmos2_5ForConditionalGeneration
login(token="YOUR_ACCESS_TOKEN")
model_id = "google/gemma-2b-it"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={
"torch_dtype": torch.bfloat16,
"use_auth_token": True
},
device_map="auto",
)
Setup OCR model
In the next step we setup the OCR model:
repo = "microsoft/kosmos-2.5"
device = "cuda:0"
dtype = torch.bfloat16
model = Kosmos2_5ForConditionalGeneration.from_pretrained(repo, device_map=device, torch_dtype=dtype)
processor = AutoProcessor.from_pretrained(repo)
RUN OCR
Now we need to have, for example, a delivery note such as this:
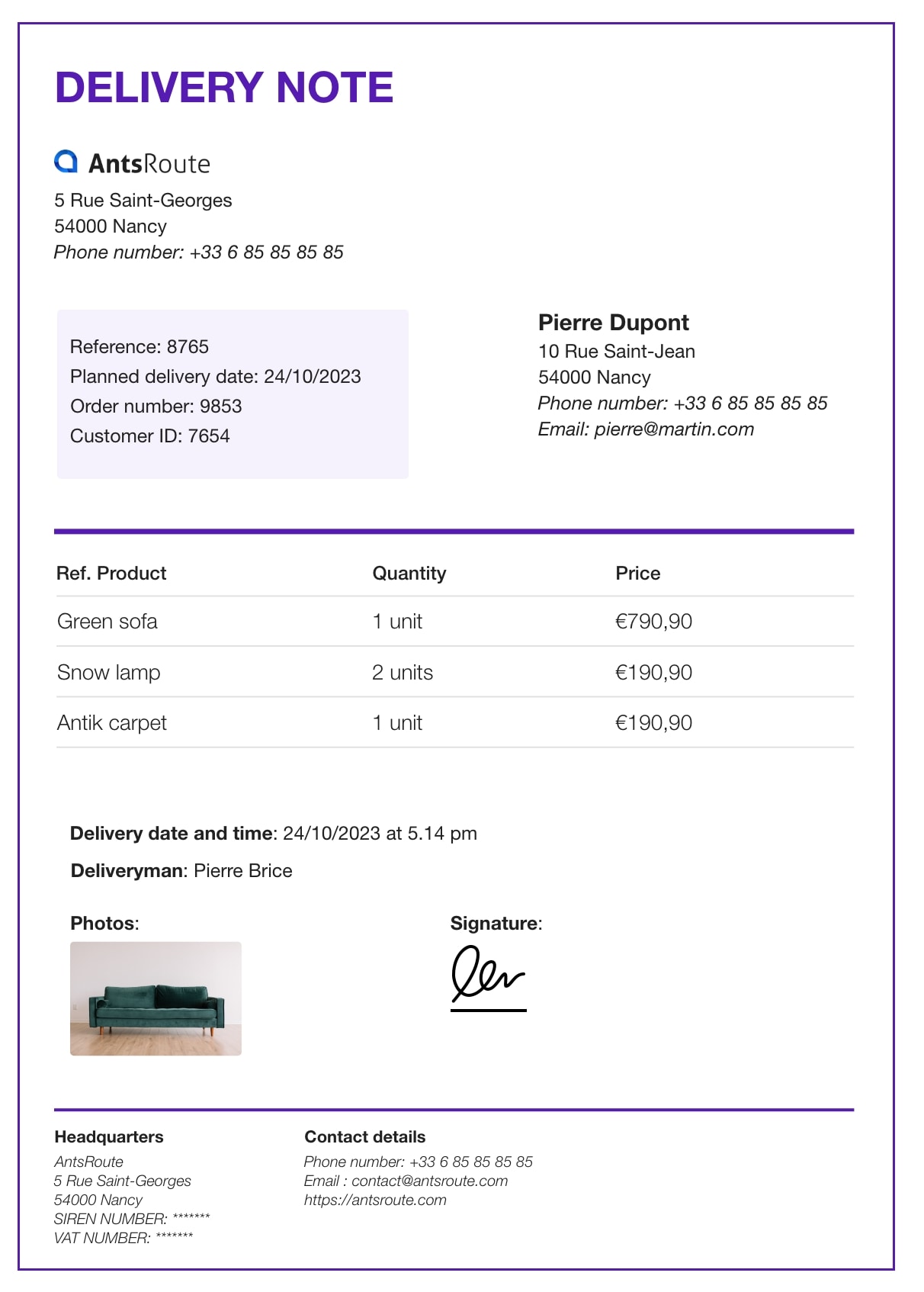
We can now process the image using the kosmos-2.5 model and draw the result.
image = Image.open(r"create-antsroute-delivery-note-7.jpg")
prompt = "<ocr>"
inputs = processor(text=prompt, images=image, return_tensors="pt")
height, width = inputs.pop("height"), inputs.pop("width")
raw_width, raw_height = image.size
scale_height = raw_height / height
scale_width = raw_width / width
inputs = {k: v.to(device) if v is not None else None for k, v in inputs.items()}
inputs["flattened_patches"] = inputs["flattened_patches"].to(dtype)
generated_ids = model.generate(
**inputs,
max_new_tokens=1024,
)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
def post_process(y, scale_height, scale_width):
y = y.replace(prompt, "")
if "<md>" in prompt:
return y
pattern = r"<bbox><x_\d+><y_\d+><x_\d+><y_\d+></bbox>"
bboxs_raw = re.findall(pattern, y)
lines = re.split(pattern, y)[1:]
bboxs = [re.findall(r"\d+", i) for i in bboxs_raw]
bboxs = [[int(j) for j in i] for i in bboxs]
info = ""
for i in range(len(lines)):
box = bboxs[i]
x0, y0, x1, y1 = box
if not (x0 >= x1 or y0 >= y1):
x0 = int(x0 * scale_width)
y0 = int(y0 * scale_height)
x1 = int(x1 * scale_width)
y1 = int(y1 * scale_height)
info += f"{x0},{y0},{x1},{y0},{x1},{y1},{x0},{y1},{lines[i]}"
#info += f"{lines[i]}"
return info
output_text = post_process(generated_text[0], scale_height, scale_width)
print(output_text)
draw = ImageDraw.Draw(image)
lines = output_text.split("\n")
for line in lines:
# draw the bounding box
line = list(line.split(","))
if len(line) < 8:
continue
line = list(map(int, line[:8]))
draw.polygon(line, outline="red")
image.save("output.png")

This successfully identifies every piece of text on the delivery note and also its position on it:
70,79,516,79,516,145,70,145,DELIVERY NOTE
70,1475,214,1475,214,1502,70,1502,Headquarters
70,1510,161,1510,161,1534,70,1534,AntsRoute
70,1534,251,1534,251,1558,70,1558,5 Rue Saint-Georges
70,1559,186,1559,186,1583,70,1583,54000 Nancy
70,1585,274,1585,274,1609,70,1609,SIREN NUMBER: ******
70,1609,252,1609,252,1633,70,1633,VAT NUMBER: ******
398,1475,558,1475,558,1502,398,1502,Contact details
398,1510,698,1510,698,1534,398,1534,Phone number: +33 6 85 85 85 85
398,1534,666,1534,666,1558,398,1558,Email : contact@antsroute.com
398,1559,586,1559,586,1583,398,1583,https://antsroute.com
74,796,206,796,206,830,74,830,Green sofa
74,863,210,863,210,896,74,896,Snow lamp
74,930,218,930,218,962,74,962,Antik carpet
74,735,217,735,217,765,74,765,Ref. Product
488,796,554,796,554,830,488,830,1 unit
488,863,568,863,568,896,488,896,2 units
488,930,554,930,554,962,488,962,1 unit
488,735,584,735,584,765,488,765,Quantity
806,796,907,796,907,830,806,830,€790,90
806,863,907,863,907,896,806,896,€190,90
806,930,907,930,907,962,806,962,€190,90
806,735,865,735,865,765,806,765,Price
705,403,903,403,903,439,705,439,Pierre Dupont
705,444,911,444,911,474,705,474,10 Rue Saint-Jean
705,478,852,478,852,508,705,508,54000 Nancy
705,512,1085,512,1085,542,705,542,Phone number: +33 6 85 85 85 85
705,546,988,546,988,575,705,575,Email: pierre@martin.com
91,439,273,439,273,467,91,467,Reference: 8765
91,477,472,477,472,506,91,506,Planned delivery date: 24/10/2023
91,516,317,516,317,546,91,546,Order number: 9853
91,556,301,556,301,584,91,584,Customer ID: 7654
91,1075,625,1075,625,1105,91,1105,Delivery date and time : 24/10/2023 at 5.14 pm
91,1125,382,1125,382,1154,91,1154,Deliveryman : Pierre Brice
91,1194,182,1194,182,1223,91,1223,Photos :
590,1194,711,1194,711,1223,590,1223,Signature :
Use LLM to process OCR model output
Now using the gemma model we can extract out wanted information quite easily using a simple prompt. In a real application we would propably want to tell the language model to do a text filling task for a json to get more reproducable results.
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
messages = [
{"role": "user", "content": f"You are an assistant that extracts the order number from my delivery note. Always reply with just the order number nothing else!. Here is the note: {output_text}"},
]
outputs = pipeline(
messages,
max_new_tokens=50,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
output_scores=False, # Don't return scores if not needed
pad_token_id=pipeline.tokenizer.eos_token_id, # Use EOS as padding
num_return_sequences=1, # Only generate one sequence if that's all you need
)
print(outputs[0]["generated_text"][-1])
This successfully gives us the wanted output:
{'role': 'assistant', 'content': '9853'}